Technology





2 Feb, 2023
5 Machine Learning Algorithm You Should Know
Machine learning has emerged as one of the most powerful technologies of the 21st century. It involves teaching machines to learn from data and make predictions or decisions based on that learning. With the increasing amount of data being generated every day, machine learning algorithms have become essential in automating decision-making processes and extracting meaningful insights from data. In this blog, we will discuss the 5 machine learning algorithms you should know.
#1 Linear Regression
Linear regression is a simple and widely used machine learning algorithm that is used to predict a continuous outcome variable based on one or more predictor variables. It works by finding the line of best fit that minimizes the sum of the squared errors between the predicted values and the actual values. One common use case for linear regression is in predicting housing prices based on factors such as location, square footage, and number of bedrooms. It can also be used in business settings to predict sales based on advertising spend or customer demographics.
#2 Logistic Regression
Logistic regression is a classification algorithm that is used to predict the probability of a binary outcome (e.g. yes/no, true/false) based on one or more predictor variables. It works by fitting a sigmoid curve to the data, which allows for the calculation of probabilities. One common use case for logistic regression is in predicting whether a customer will churn (i.e. stop using a product or service). It can also be used in medical settings to predict the likelihood of a patient developing a certain disease based on their symptoms and other factors.
#3 Decision Trees
Decision trees are a popular machine learning algorithm for both classification and regression tasks. They work by recursively splitting the data into smaller subsets based on the most important features until a stopping criterion is met. The resulting tree can be used to make predictions on new data. One common use case for decision trees is in predicting whether a customer will purchase a certain product based on their demographic and purchase history. It can also be used in medical settings to predict the likelihood of a patient having a certain condition based on their symptoms and test results.
#4 Random Forest
Random forests are an ensemble learning algorithm that combines multiple decision trees to improve the accuracy and reduce overfitting. They work by creating multiple decision trees on randomly sampled subsets of the data and then aggregating the results. One common use case for random forests is in predicting whether a customer will default on a loan based on their credit history, income, and other factors. It can also be used in image classification tasks to identify objects in photos or videos.
#5 K-Nearest Neighbors
K-nearest neighbors (KNN) is a simple and intuitive machine learning algorithm for classification and regression tasks. It works by finding the K closest data points to a new data point and using their labels or values to make a prediction. One common use case for KNN is in predicting whether a customer will click on an ad based on their browsing history and other factors. It can also be used in weather forecasting to predict temperature or precipitation based on historical data.
Conclusion
These five machine learning algorithms are just a small sample of the many techniques that Data Scientists use to analyze and predict patterns in data. Each algorithm has its strengths and weaknesses, and the choice of which one to use depends on the specific problem at hand. By understanding these common algorithms, Data Scientists can build more accurate models and make better predictions, leading to improved decision-making and business outcomes.
15 Feb, 2023
Boosting Your Model's Accuracy: Tips & Tricks
Before we dive into the tips and tricks for improving your machine learning model's accuracy, it's important to understand what accuracy means in the context of machine learning. Simply put, accuracy refers to how well a model is able to predict the correct output based on the input data. In order to measure accuracy, we typically use metrics such as precision, recall, and F1 score. These metrics give us a more nuanced understanding of how well our model is performing and where there may be room for improvement.
#1 Feature Engineering
One of the most effective ways to improve your model's accuracy is through feature engineering. Feature engineering involves selecting and transforming the input data in a way that makes it easier for the model to learn patterns and make accurate predictions. Some common techniques for feature engineering include one-hot encoding, scaling, and normalization. By carefully selecting and transforming our features, we can help our model better understand the underlying relationships in the data and make more accurate predictions.
#2 Hyperparameter Tuning
Another key factor in improving model accuracy is hyperparameter tuning. Hyperparameters are settings that we choose before training the model, such as the learning rate, number of hidden layers, and regularization strength. By carefully selecting these hyperparameters and tuning them over time, we can help our model achieve better accuracy and avoid overfitting. Techniques such as grid search and random search can help us explore the space of possible hyperparameters and find the best combination for our specific problem.
#3 Ensemble Methods
Ensemble methods involve combining multiple models together to make more accurate predictions. By training several models on the same data and then aggregating their predictions, we can often achieve better accuracy than any individual model could on its own. Common ensemble methods include bagging, boosting, and stacking. These techniques can be especially effective when dealing with noisy or complex datasets where a single model may struggle to capture all the underlying patterns.
#4 Regularization
Regularization is a technique for preventing overfitting in machine learning models. Overfitting occurs when a model becomes too complex and starts to fit noise in the data rather than the underlying patterns. Common regularization techniques include L1 and L2 regularization, dropout, and early stopping. By applying these techniques, we can help our model generalize better to new, unseen data and improve overall accuracy.
Conclusion
Improving your machine learning model's accuracy requires a combination of careful feature engineering, hyperparameter tuning, ensemble methods, and regularization. By following these tips and tricks, you can help your model achieve better accuracy and make more accurate predictions. Remember that machine learning is an iterative process, and it may take some trial and error to find the best combination of techniques for your specific problem. But with persistence and a willingness to experiment, you can achieve great results and unlock the full potential of your data.
Leave a Reply

20 Feb, 2023
Revolutionizing Transportation: The Future of Autonomous Vehicles with Machine Learning
Autonomous vehicles are the future of transportation, and machine learning technologies are driving their development. The ability of machines to learn from data and make decisions without human intervention is revolutionizing the automotive industry. In this presentation, we will explore the latest advances in autonomous vehicle technology and how machine learning algorithms are being used to improve safety, efficiency, and convenience.
#1 The Evolution of Autonomous Vehicles
Autonomous vehicles have come a long way since the first self-driving car was developed in the 1980s. Early attempts were limited by the technology available at the time, but recent advances in sensors, processors, and software have made fully autonomous vehicles a reality. Today's autonomous vehicles use a combination of cameras, lidar, radar, and GPS to navigate roads and avoid obstacles. Machine learning algorithms are used to analyze sensor data and make decisions about steering, acceleration, and braking.
#2 Challenges and Opportunities
While autonomous vehicles hold great promise for the future, there are still many challenges that must be overcome. One of the biggest is ensuring the safety of passengers and other road users. Machine learning algorithms must be able to make split-second decisions in complex situations, such as avoiding collisions or navigating through construction zones. Despite these challenges, there are also many opportunities presented by autonomous vehicles. They have the potential to reduce traffic congestion, improve fuel efficiency, and provide greater mobility for people who are unable to drive themselves. Machine learning technologies will play a crucial role in realizing these benefits.
#3 The Role of Machine Learning
Machine learning algorithms are essential for the development of autonomous vehicles. They enable vehicles to learn from experience and adapt to changing environments. By analyzing vast amounts of sensor data, machine learning algorithms can identify patterns and make predictions about future events. One of the key challenges in developing autonomous vehicles is ensuring that they are able to operate safely in all conditions. Machine learning algorithms can help by identifying potential hazards and predicting how other road users will behave. They can also be used to optimize vehicle performance, such as improving fuel efficiency or reducing wear and tear on tires.
#4 The Future of Autonomous Vehicles
The future of autonomous vehicles is bright, with many exciting possibilities on the horizon. As machine learning technologies continue to advance, we can expect to see even more sophisticated autonomous vehicles that are capable of navigating complex environments and interacting with other road users. In addition to passenger cars, autonomous vehicles will also have applications in logistics, transportation, and other industries. They have the potential to revolutionize the way goods are transported and distributed, reducing costs and increasing efficiency.
Conclusion
Autonomous vehicles are no longer a pipe dream - they are a reality that is rapidly evolving. Machine learning technologies are driving this evolution, enabling vehicles to learn from data and make decisions without human intervention. As we continue to explore the future of autonomous vehicles, it is clear that machine learning will play an increasingly important role. The possibilities are endless, and the future looks bright for this exciting and rapidly evolving field.
Leave a Reply

10 Mar, 2023
Recommendations: Crafting a Recommender System with Scikit-Learn
Recommender systems are widely used in e-commerce, social media, and other industries to provide personalized recommendations to users. These systems use machine learning algorithms to predict a user's preferences based on their past behavior and the behavior of similar users. In this presentation, we will explore how to build a recommender system from scratch using Python and the Scikit-Learn library. We will cover the different types of recommender systems, the data required for training these systems, and the evaluation metrics used to measure their performance.
#1 Types of Recommender Systems
There are two main types of recommender systems: content-based and collaborative filtering. Content-based systems recommend items based on their similarity to items previously liked by the user. Collaborative filtering systems recommend items based on the preferences of users who have similar tastes to the user being recommended to. Hybrid recommender systems combine both content-based and collaborative filtering approaches to provide more accurate recommendations. In this presentation, we will focus on collaborative filtering as it is the most commonly used approach in industry.
#2 Data Preparation for Recommender Systems
The data required for training a recommender system typically consists of user-item interactions, such as ratings or purchases. This data needs to be preprocessed and transformed into a format that can be used by machine learning algorithms. One common preprocessing step is to normalize the data to account for differences in user behavior. Another important step is to split the data into training and test sets to evaluate the performance of the recommender system. In this presentation, we will use the MovieLens dataset as an example for building our recommender system.
#3 Building a Collaborative Filtering Recommender System
To build a collaborative filtering recommender system, we first need to create a user-item matrix that represents the interactions between users and items. We can then apply matrix factorization techniques, such as singular value decomposition (SVD) or alternating least squares (ALS), to decompose the matrix into latent factors. These latent factors represent the underlying preferences and characteristics of users and items. We can then use these factors to make recommendations for new items to users. In this presentation, we will use SVD to build our recommender system.
#4 Evaluating Recommender System Performance
There are several evaluation metrics used to measure the performance of a recommender system, such as mean absolute error (MAE) and root mean squared error (RMSE). These metrics measure the difference between the predicted ratings and the actual ratings for a set of test data. Another important metric is precision, which measures the percentage of recommended items that the user actually likes within the top k recommendations. In this presentation, we will use MAE and precision to evaluate the performance of our recommender system.
Conclusion
In conclusion, building a recommender system from scratch using Python and the Scikit-Learn library is a complex but rewarding task. Collaborative filtering is a popular approach for building recommender systems, and matrix factorization techniques such as SVD can be used to decompose user-item interactions into latent factors. Evaluating the performance of a recommender system is crucial to ensure that it provides accurate recommendations to users. By following the steps outlined in this presentation, you can build your own recommender system and provide personalized recommendations to your users.
Leave a Reply
27 Mar, 2023
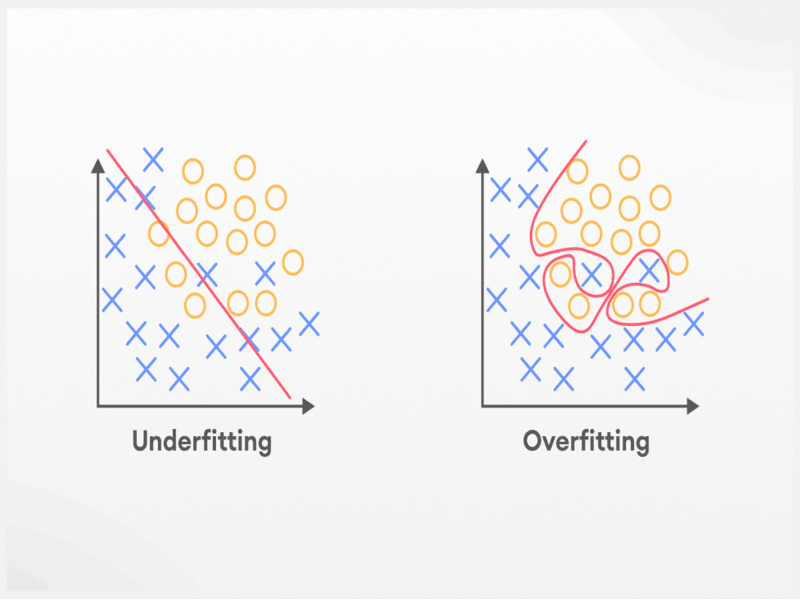
Taming the Machine: Tips and Tricks to Conquer Model Overfitting & Underfitting
Machine learning models are trained on a dataset to make predictions on new data. However, sometimes these models may not generalize well and perform poorly on new data due to overfitting or underfitting. Overfitting occurs when a model is too complex and tries to fit the noise in the training data, resulting in poor performance on new data. Underfitting occurs when a model is too simple and cannot capture the underlying patterns in the data.
#1 Increase the amount of Data
One of the best ways to combat overfitting and underfitting is to increase the amount of data. This can help the model to capture the patterns in the data better, leading to better generalization to new data.
#2 Cross-Validation
One way to prevent overfitting is by using cross-validation. Cross-validation involves splitting the data into multiple subsets and training the model on different combinations of these subsets. This helps to evaluate the model's performance on different subsets of the data and prevents overfitting. K-fold cross-validation is a common technique where the data is split into k subsets and the model is trained k times, each time using a different subset as the validation set and the remaining subsets as the training set.
#3 Regularization
Another way to prevent overfitting is by using regularization techniques. Regularization adds a penalty term to the loss function during training, which discourages the model from fitting the noise in the data. L1 and L2 regularization are two common techniques. L1 regularization adds a penalty proportional to the absolute value of the weights, while L2 regularization adds a penalty proportional to the square of the weights.
#4 Ensemble methods
Ensemble methods combine multiple models to improve performance and reduce overfitting. One popular ensemble method is bagging, which involves training multiple models on subsets of the data and averaging their predictions. Another ensemble method is boosting, which involves training multiple models sequentially, with each model focusing on the examples that the previous models got wrong.
#5 Feature engineering
Feature engineering involves selecting or creating features that are relevant to the problem at hand. Good feature engineering can help prevent overfitting by reducing the complexity of the model. One common technique for feature engineering is dimensionality reduction, which involves transforming the data into a lower-dimensional space while preserving the important information.
Conclusion
In conclusion, overfitting and underfitting are common problems in machine learning that can be addressed using various techniques such as cross-validation, regularization, ensemble methods, and feature engineering. By understanding these techniques and applying them appropriately, we can build more robust and accurate machine learning models.
Leave a Reply